LLMs can have outdated or incorrect internal knowledge, e.g., about a formal head of state, a deprecated API, or a wrong mathematical procedure.
Common mitigations (in-context learning or knowledge editing) introduce Knowledge Conflicts between the new facts and the model's internal beliefs, but typically, LLMs can often recall a newly injected fact.
However, the critical question of whether models can reason with injected knowledge that conflicts with their parametric beliefs remains underexplored, which we call the problem of Knowledge Propagation.
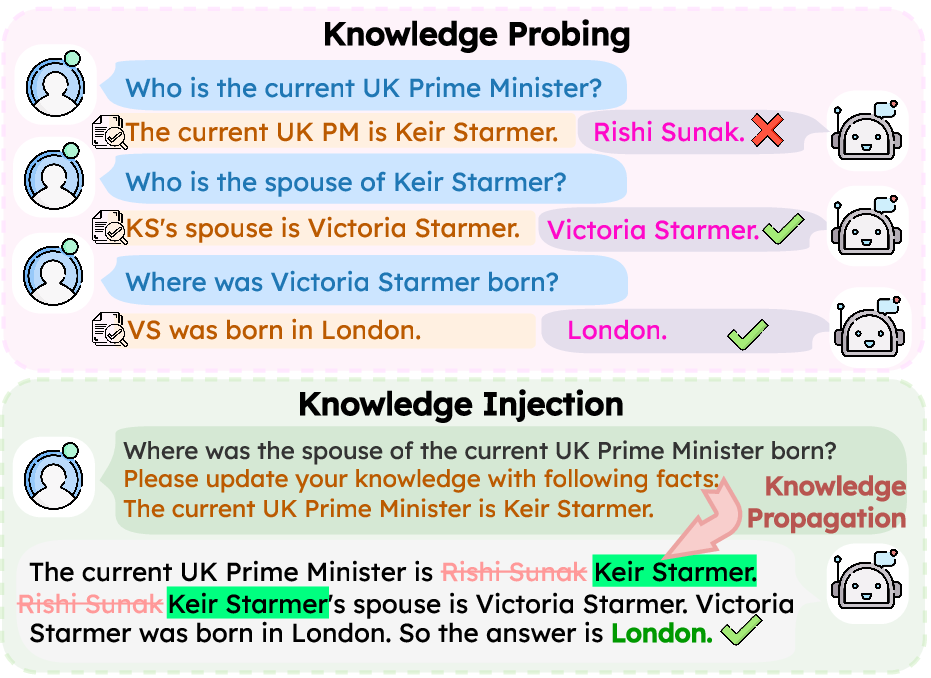
Two-stage evaluation: Knowledge Probing → Knowledge Injection.
We introduce Track to evaluate how LLMs propagate conflicting knowledge through multi-step reasoning. Unlike prior benchmarks, Track introduces multiple, realistic knowledge conflicts across diverse, reasoning-intensive domains to mirror real-world complexity and test true knowledge propagation. It uses a two-stage framework: ① Knowledge Probing first identifies each model's specific knowledge gaps, then ② Knowledge Injection provides conflicting facts at inference time to test whether the model can propagate them through reasoning.
Key Takeaways:
- LLMs exhibit polarized knowledge confidence. They either know facts with high certainty or are clearly unaware.
- Providing correct but conflicting facts yields limited gains and can even hurt performance.
- Failures stem from both inability to integrate facts faithfully and flawed reasoning even when integration succeeds.


